
As many of you know, mainstream support for SQL Server 2008 and 2008R2 ended back on July 9th of 2014. Extended support is active now and that is set to expire on July 9th of 2019. After July 9th, no security fixes will be made available. It is extremely important for you to move all your database off of and 2008/2008R2 instances to a supported instance of SQL Server.
We started our process back in 2017 to understand some of the application changes required for the database move. We have a mix of custom and vendor applications. The main goal of the migration was to update our documentation around the database & application relationships and bring all our custom databases up to SQL16 standards.
We’re big fans of OneNote. It is a great way to document our databases and applications along with projects like our migration off of SQL Server 2008/2008R2. We created a template checklist that we could use for each custom database that we created. For the vendor databases, it was more of a manual process because each vendor had a
The checklist consists of these pre-migration steps:
- Compare schema between prod and dev/test. We want to make sure we don’t overwrite new objects under dev/test if they have not been deployed to production. Our main gain was to try and use a copy of the production database as a fresh start for dev/test.
- Use Microsoft’s Data Migration Assistant to scan the SQL08/08R2 database for any objects that might cause issues under SQL16.
- Do a metadata search across other databases no the same instance. Because some of our databases cross-reference other databases, we wanted to search all objects and look for references to the current database that we are migrating. If there are references, we need to validate they are in use, and if so, migrate all databases together.
- Search through SSRS & SSIS for data sources that use the database that we are migrating. If we find a reference, we need to make sure and update all SSRS & SSIS projects with the new connection string.
- The above findings were discussed as a group to determine the best migration steps.
Once the plan was approved by all members of the team, we moved forward with the dev/test migration so the developers had a platform to test against. Here are the high level steps for our migration script:
- Restore a
copy of the production database under dev/test. - Script out the permissions under the old instance so we can make sure and carry them over.
- Drop any production database users from the dev/test restored
database . - Create the server and database principals for the applications to authenticate with.
- Set the correct database owner.
- Update the compatibility level to 130.
- Create a SECONDARY file group and move all user objects to the new file group.
- Create database security roles and assign database principals.
- Enable query store
- Run SQL Vulnerability Assessment and baseline/correct any issues.
- Update any SSRS & SSIS projects under dev/test with new connection strings.
- Test
- Test
- Test
Once we were happy with testing, we scheduled the production cut-over with our business partners and ran through the same steps as above. We are more than 75% of the way through our SQL08/08R2 databases and are on target to have everything migrated by June. This project would have not been possible without scripts posted by members of the SQL Server Community. Special shout outs to Aaron Bertrand for his script to move objects between file groups, Jason Strate for his script to index all FKs, and S. Kusen for his script to script out permissions within a database.
Doug Purnell
@SQLNikon
sqlnikon@gmail.com
https://sqlnikon.com










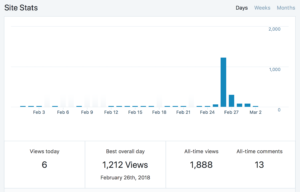 Back in February one of my blog posts was highlighted on Brent Ozar Unlimited’s
Back in February one of my blog posts was highlighted on Brent Ozar Unlimited’s